How to speak spanish like a colombian drug lord!
I've been living in Puerto Rico for 4 years but two of those have been COVID and so I haven't been able to practice Spanish as much as I'd like. So to speed up my learning I've decided I want to watch a lot of spanish speaking television to start training my ears, but to do this I need a baseline of words I understand to be able to even know what they are saying!
Learning through apps like Duolingo, Drops, etc start with weird topics like vegetables that don't get you to a very good baseline for actually understanding daily conversations, so I think consuming TV is a better use of my time.
Subtitles
I've decided the way to understand what the best words to study are is to download every subtitle for every episode of a show I want to watch and then count each word. The more a word is spoken the more important it is for me to know it since I'll be hearing it a lot in the show.
I'm going to download subtitles from Netflix. Subtitles in Netflix are in WebVTT format, which looks like this:
248
00:17:58.285 --> 00:18:01.163 position:50.00%,middle align:middle size:80.00% line:79.33%
Yo de verdad espero que ustedes
me vean como una amiga, ¿mmm?
249
00:18:01.247 --> 00:18:02.539 position:50.00%,middle align:middle size:80.00% line:84.67%
No como una madrastra.
250
00:18:04.250 --> 00:18:06.127 position:50.00%,middle align:middle size:80.00% line:84.67%
Yo nunca te vi como una madrastra.It gives you a start time, end time, and the text on the screen. So my first process was parsing this format and just turning it into a list of words using https://github.com/glut23/webvtt-py.
Dummy parsing
What I basically did was text.split(" ") and started counting the words. This approach was quick and painless but it had a few downs falls. Some words look the same when in reality they are not and so this meant I'd have to study every meaning of a word even if it was more rare.
An example of this is the word "como", you can say:
- Haz como te digo: "Do as I say", where como means "as"
- como tacos todos los dias: "I eat tacos every day", where como is a conjugated form of the verb "to eat"
I need to know which version of a word is being used so I can count it properly.
Regular Expressions are always the answer
I couldn't figure out what the word was without it being in a complete sentence, but subtitles are fragments. They are split up into timings for displaying on the screen but they don't include entire sentences. For example, it might look like this:
23
00:01:21.960 --> 00:01:23.520 position:50.00%,middle align:middle size:80.00% line:84.67%
Solo las que luchan por ellos
24
00:01:23.680 --> 00:01:25.680 position:50.00%,middle align:middle size:80.00% line:84.67%
consiguen sus sueños.I want to detect the start of a sentence and the end of a sentence and then combine it, so that you end up with "Solo las que luchan por ellos consiguen sus sueños.". My first thought was a regular expression on punctuation. This worked well most of the time but there were enough exceptions to the rule that it broke often on generated a lot of broken sentences:
- Abbreviations like "EE. UU" for estados unidos (united states)
- Ellipsis
Splitting on spaces also didn't work for identifying the parts of speech since I needed the context around the word.

Natural Language Processing
So to solve my pain I decided to grab https://spacy.io/ and do some NLP on the subtitles so that I could identify the proper parts of speech and get an accurate representation of the words I needed to learn.
The way spaCy works is you can send it a sentence and it'll return you a set of tokens:
>>> import spacy
>>> nlp = spacy.load("es_core_news_sm")
>>> [x.pos_ for x in nlp("Hola, como estas?")]
['PROPN', 'PUNCT', 'SCONJ', 'PRON', 'PUNCT']So now I could identify the parts of speech and pull sentences together through end of sentence punctation. The first thing I did was generate a CSV of sentences that looked like this:
| sentence | start | end | show | file |
|---|---|---|---|---|
| Si no, le voy a cortar todos los deditos | 00:00:20.605 | 00:00:24.125 | El marginal | El marginal S02E02 WEBRip Netflix es[cc].vtt |
Once I had a CSV of sentences I could send those back through spaCy for NLP and then start counting words, to generate another CSV:
| word | pos | show | file |
|---|---|---|---|
| a | ADP | El marginal | El marginal S02E02 WEBRip Netflix es[cc].vtt |
| cortar | VERB | El marginal | El marginal S02E02 WEBRip Netflix es[cc].vtt |
| todos | PRON | El marginal | El marginal S02E02 WEBRip Netflix es[cc].vtt |
From there I had all the data I needed! So now it was time to start doing some data analysis!
Data analysis
Using a jupyter notebook ( https://jupyter.org/ ) I grabbed pandas ( https://pandas.pydata.org/ ) and read in my CSVs to start analyzing the results.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
pd.set_option('display.max_rows', 1000)
words = pd.read_csv('word_data.csv.gz', compression='gzip', delimiter=',')The words dataframe is built up out of the second table I showed above with just words and their parts of speech. I started off grouping the dataset by the word so I could get a count for how many times it was spoken in every series I parsed:
grouped_result = (words.groupby(words.word).size()
.sort_values(ascending=False)
.reset_index(name='count')
.drop_duplicates(subset='word'))
grouped_result.head(300)Which returned a list of words and their count:
word count
0 que 94430
1 no 75931
2 a 70968
3 de 67982
4 ser 64226
5 la 52143
6 y 44390
7 estar 37819
8 el 35920Now I wanted to identify where my diminishing returns would be. Is there a set of words that I must learn because they are spoken so often that I wouldn't understand a conversation if they weren't in my vocabulary?
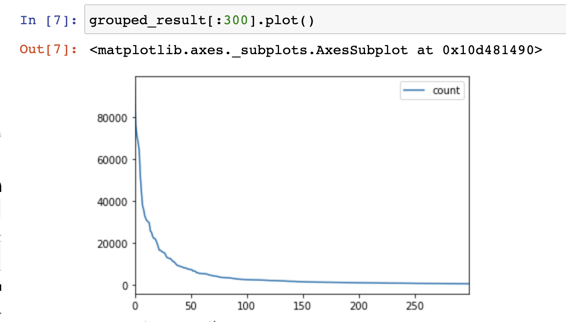
As you can see in this chart, the usage for words drops off at around the ~200 mark. So there are basically 150 words I must know and then the rest are equally important. I wasn't quite happy with this because some parts of speech are higher priority than others, for example I think having a strong understanding of the popular verbs will go a long way. So I also wanted to identify what are the most important verbs to learn:
grouped_verbs = (words[words.pos == 'VERB'].groupby(['word', 'pos']).size()
.sort_values(ascending=False)
.reset_index(name='count')
.drop_duplicates(subset='word'))
grouped_verbs.head(50)Which got me this:
word pos count
0 tener VERB 22072
1 hacer VERB 14946
2 ir VERB 12570
3 decir VERB 11314
4 querer VERB 11083
5 ver VERB 10269
6 estar VERB 9780
7 saber VERB 8704
8 ser VERB 7674
9 dar VERB 5722
10 pasar VERB 5528
11 hablar VERB 5355
12 venir VERB 5145
13 creer VERB 4895
14 salir VERB 3395Verbs had a slightly different drop-off pattern when I targeted them directly:
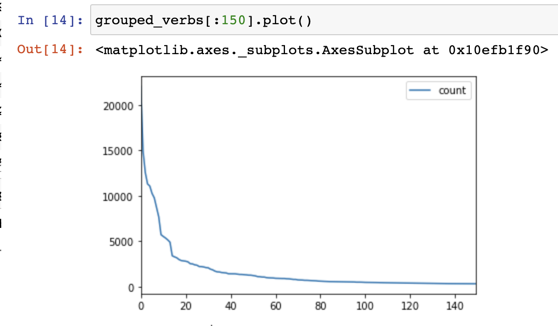
I get a big bang for my buck by learning those top 40 verbs. Nouns on the other hand are much more spread out and most are evenly distributed:
word pos count
0 gracias NOUN 4676
1 favor NOUN 4625
2 señor NOUN 4116
3 verdad NOUN 3566
4 vida NOUN 2673
5 hombre NOUN 2601
6 madre NOUN 2597
7 vez NOUN 2537
8 tiempo NOUN 2492
9 hijo NOUN 2215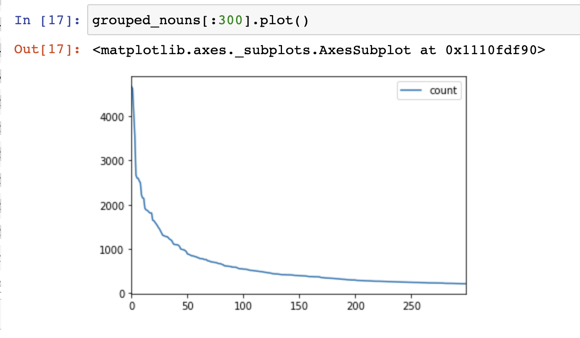
So then I thought to myself... How much of a show would I understand if I just learned these most important words? So I started by excluding some of the easy parts of speech and focused on the most important:
find_important_words = (words[~words.pos.isin(['PRON', 'CONJ', 'ADP', 'ADV', 'SCONJ', 'AUX', 'INTJ'])].groupby(['word', 'pos']).size()
.sort_values(ascending=False)
.reset_index(name='count')
.drop_duplicates(subset='word'))
find_important_words.head(50)The top 20 were all verbs except for bueno and gracias. So now with my list of what I considered "important words" I plotted it to find what amount of words I wanted to learn:
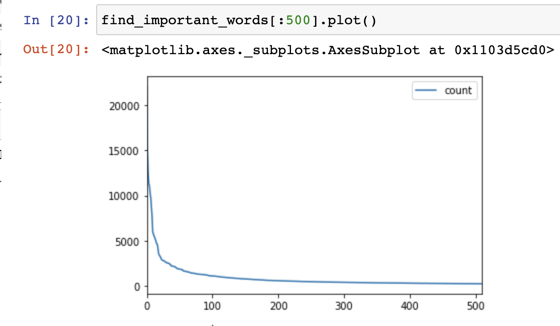
It looks like 200 learned words would give me a reasonable amount of understanding for a series, so I decided to calculate how much of a series I would understand if I learned just those first 200 words:
percentages = {}
for show_name in words['media'].drop_duplicates().values:
words_in_show = (words[words.media == show_name].groupby(words.word).size()
.sort_values(ascending=False)
.reset_index(name='count')
.drop_duplicates(subset='word'))
total_words_handled = 0
for word in grouped_result['word'][:200]:
values = words_in_show[words_in_show.word == word]['count'].values
if values.size > 0:
total_words_handled += values[0]
percentages[show_name] = total_words_handled / words_in_show.sum().loc['count']Now I had a table that would show me what percentage of the spoken words were covered by the first 200 words in my list:
p_df = pd.DataFrame(percentages.items(), columns=['show', 'percentage'])
p_df = p_df.sort_values(by='percentage')
p_df['percentage'] = p_df['percentage'] * 100
pd.options.display.float_format = '{:,.2f}%'.format
p_df| Show | Percentage |
|---|---|
| Verónica | 64.24% |
| El ciudadano ilustre | 65.28% |
| El Chapo | 66.68% |
| Neruda | 66.89% |
| La casa de papel | 67.56% |
| El Ministerio del Tiempo | 68.03% |
| Club de Cuervos | 68.19% |
| El marginal | 68.47% |
| Ingobernable | 68.59% |
| Pablo Escobar | 70.20% |
| Fariña | 70.95 |
| La Reina del Sur | 71.52% |
| Gran Hotel | 73.15% |
| Las chicas del cable | 73.58% |
| Élite | 73.78% |
| La Piloto | 74.03% |
| El bar | 74.07% |
| La casa de las flores | 75.40% |
| Tarde para la ira | 75.59% |
But living in Puerto Rico, one thing I've realized is speed of speech is also important. I have a much easier time speaking with people from Colombia and Mexico than I do with Puerto Ricans because they speak so much faster. So even though I could understand 75% of "Tarde para la ira" if I learned the 200 words, I want to make sure they are speaking at a pace I could understand as well.
So I loaded up the other CSV file that was the full sentences and added a "time per word" column:
sentences = pd.read_csv('sentences.csv.gz', compression='gzip', delimiter=',', parse_dates=['start', 'end'])
sentences['total_time'] = (sentences['end'] - sentences['start']).dt.total_seconds()
sentences['word_count'] = sentences['sentence'].str.split().str.len()
sentences['time_per_word'] = sentences['total_time'] / sentences['word_count']Then I was able to have a speed rating for each show:
sentence_group = sentences.groupby([sentences.media])
sentence_group.time_per_word.mean().reset_index().sort_values('time_per_word')| media | time_per_word |
|---|---|
| Gran Hotel | 0.58 |
| El Chapo | 0.59 |
| Las chicas del cable | 0.61 |
| Élite | 0.63 |
| Ingobernable | 0.64 |
| El Ministerio del Tiempo | 0.64 |
| Fariña | 0.65 |
| El ciudadano ilustre | 0.67 |
| Neruda | 0.68 |
| La Piloto | 0.69 |
| La casa de papel | 0.70 |
| El bar | 0.70 |
| Verónica | 0.72 |
| La Reina del Sur | 0.75 |
| Club de Cuervos | 0.76 |
| El marginal | 0.76 |
| Pablo Escobar | 0.77 |
| Tarde para la ira | 0.77 |
| La casa de las flores | 0.81 |
Luckily the two series that have the least amount of vocabulary also speak the slowest! So these will be the series I start with. The final question I wanted to answer is "What are the top words I'm missing for a series". Since I'll know 75% of the series from the top 200 words, I'm hoping there are some top words from a specific series that I can also learn to get an even higher understanding.
First, find which words are in each show but not in the top 200:
missing_words_by_show = {}
for show_name in words['media'].drop_duplicates().values:
words_in_show = (words[words.media == show_name].groupby(words.word).size()
.sort_values(ascending=False)
.reset_index(name='count')
.drop_duplicates(subset='word'))
frequency_words = grouped_result['word'][:200]
missing_words = words_in_show[~words_in_show.word.isin(frequency_words.values)]
missing_words_by_show[show_name] = missing_wordsThen we were able to grab them per show:
missing_words_by_show['La casa de las flores'].head(50)
word count
31 mamá 252
70 florería 87
98 perdón 56
102 sea 54
116 además 44
126 ahorita 40
132 cárcel 38
133 fiesta 38So adding those few words to my vocabulary will also give me a better understanding of the series.
Conclusion
I believe a data-driven approach to language learning will be an effective way to get me speaking better spanish. It was a ton of fun to play with spaCy, pandas, and jupyter as well!
I'll improve the data analysis over time as well but I do believe this is a pretty good starting point!
